深度学习|模型推理:端到端任务处理

引言
通过前文「深度学习|感知机:神经网络之始」中 XOR Gate 的示例,我们知道叠加层可以增强感知机的表达能力。神奇的是,实际上通过简单的 NAND Gate 叠加就可以实现计算机这样复杂的系统。理论上只要知道怎么设置多层感知机的层次结构、层次间的运算权重,我们可以通过感知机表达任意计算机可以编码完成的逻辑。
但不幸的是,如何找到合适的层次结构与运算权重是一个相当复杂的过程,如果完全由人工来设置,这将几乎是不可能完成的工作,这也是神经网络第一次遇冷的原因。
端到端的能力
神经网络是一种机器学习算法,它的目的是自动学会端到端任务的处理逻辑。这里说的端到端,便是指任务的最初输入端到最终输出端。
我们把计算机上运行的任意任务看作端到端的任务,正常实现这样的任务,需要以显式编程的方式实现输入端到输出端的固定处理逻辑。当处理逻辑发生改变,对应的编程实现也需要随之改变。
学习过程:若以神经网络来实现这一任务,以任务的处理逻辑为神经网络的学习目标,通过神经网络的学习(即在某个适当的网络层次结构上自适应找到一组正确的权重参数)就能自动实现该任务从输入端到输出端的处理逻辑。这一过程就是神经网络模型的学习过程,详情我们将在后续的篇章中展开探讨。
神经网络的学习过程需要根据训练数据(任务的输入数据与输出数据)不停调整神经元之间的权重参数(连接权和阈值,统称权重参数,神经网络学到的东西都在权重参数中),直至达到一个“理想状态”。
泛化能力:这种通过学习获得的处理逻辑,往往能够覆盖一些人工编码覆盖不到的逻辑,甚至处理一些同类但模型未曾见过的案例,也即有了泛化能力。
即使端到端任务的处理逻辑发生改变,某种程度上,也只需通过新的训练数据学得新的处理逻辑,就能适应新的任务。不再需要通过人工改变编码的方式来适配无休止变化的新规则。
任务与模型简介
上文介绍了神经网络模型的端到端处理能力,接下来我们以手写数字识别任务为例,尝试使用神经网络的推理能力来处理该问题,从而更一般地演示和梳理神经网络的推理过程。
神经网络的推理,就是利用已经学习好的神经网络模型,计算新的输入样例的对应输出。也即在已知网络层次结构、已知网络权重参数的固定神经网络计算公式上,进行固定函数的计算的过程。
手写数字识别
手写数字识别任务是一项计算机视觉任务,其目的是使用训练数据(这里采用的是 MNIST 数据集)建立数字图像识别模型,从而识别任意图像中的数字。
这项任务的主要挑�战在于训练模型能够准确地识别手写数字的特征和模式,在输入的图像中找出对应的数字。通过训练模型,它可以学习到不同数字之间的差异,并根据输入图像中的像素值进行预测和分类,从而实现手写数字的自动识别。
这项任务在许多领域有广泛的应用,如 ORC(Optical Character Recognition,光学字符识别)、智能表单处理、邮政编码识别等。
数据准备
MNIST 数据集是一组由美国高中生和人口调查局员工手写的 70000 个数字图片,每张图片都用其代表的数字标记。因广泛被应用于机器学习入门,被称作机器学习领域的 “Hello World!”。因其适应性,也常被用于测试新分类算法的效果。
首先我们需要下载与加载 MNIST 数据,使用 Scikit-Learn 实现如下:
前置准备:
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
Scikit-Learn使用 Python 的urllib包通过HTTPS协议下载数据集,这里全局取消证书验证(否则Scikit-Learn可能无法建立 ssl 连接);
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
print(mnist.keys())
# dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])
简单认识 MNIST 数据:
### 查看数据集
X, y = mnist["data"], mnist["target"]
print(X.shape)
# (70000, 784)
print(y.shape)
# (70000,)
print(y[:1][0])
# 5
print(X[:1].shape)
# (1, 784)
从此处我们可以看到,MNIST 数据集 X 共有 70000 个图片数据,每个图片数据包含 784 个数值表示的 28 28 的位图值,y 是这 70000 个图片数据对应代表的数字。
第一张图片数据对应的数字是 5。使用 Matplotlib 可以轻易将训练集的第一个输入数据转化为位图��打印出来:
import matplotlib.pyplot as plt
import matplotlib as mpl
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.binary, interpolation="nearest")
plt.axis("off")
some_digit = X[:1].to_numpy()
plot_digit(some_digit)
plt.show()

图 1:手写数字 5,MNIST 数据集中第一个输入数据的位图展示
训练集与测试集
我们可以将 MNIST 数据集分成训练集(前 6 万张图片)和测试集(最后 1 万张图片)。
也可以对训练集进行混洗,保障在做交叉验证时所有折叠的实例分布相当。有一些算法对训练实例的顺序敏感,连续输入相同的实例可能导致性能不佳,也有一些情况时间序列也是实例特征(如股市架构或天气状态),则不可混洗数据集。
x_train, x_test, t_train, t_test = X[:60000], X[60000:], y[:60000], y[60000:]
将数据分为训练集输入数据 x_train,测试集输入数据 x_test,训练集输出标签 t_train,测试集输出标签 t_test。
其中 x_train 包含 60000 个图片数据,每个图片数据包含 784 个数值表示的 28 28 的位图值,t_train 则是这 60000 个图片数据对应代表的数字。x_test 包含 10000 个与 x_train 相同结构的图片数据,t_test 是这 10000 个图片数据对应代表的数字。
print('训练集输入数据的形状:', x_train.shape) # (60000, 784)
print('训练集输出标签的形状:', t_train.shape) # (60000,)
print('测试集输入数据的形状:', x_test.shape) # (10000, 784)
print('测试集输出标签的形状:', t_test.shape) # (10000,)
# 训练集输入数据的形状: (60000, 784)
# 训练集输出标签的形状: (60000,)
# 测试集输入数据的形状: (10000, 784)
# 测试集输出标签的形状: (10000,)
模型介绍
我们假设已有一个学好的手写数字图像识别神经网络模型(这里先跳过神经网络的学习过程,先掌握如何使用模型,再去了解如何训练制作该模型),如图 2,现在我们的目的就是使用该模型识别 MNIST 数据集中的任意图片中的数字。
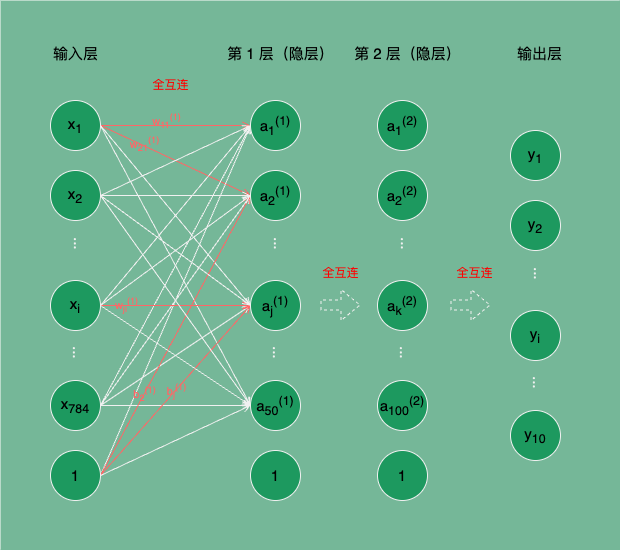
图 2:手写数字图像识别的神经网络
图 2 所示是一个三层神经网络,输入层有 784 个神经元,第 1、2 层隐层分别有 50 和 100 个功能神经元对输入信号进行处理,输出层有 10 个神经元,输出层的 10 个输出分别对应输入图片被该网络推理判定为数字 0 ~ 9 的概率。
我们统一一下神经网络中权重、偏置、输入层神经元、隐藏层神经元等的符号表示:
- 表示输入层的第 i 个神经元的输入;假设输入层有 n 个神经元, 表示 n 个 x 组成的形状为 (n,) 的矩阵。
- 表示第 k-1 层网络的第 j 个神经元到第 k 层网络的第 i 个神经元之间的计算权重;假设第 k-1 层有 n 个神经元,第 k 层有 m 个神经元, 表示第 k-1 层到第 k 层间 n m 个 w 组成的形状为 (n, m) 的矩阵。
- 表示第 k-1 层到第 k 层第 i 个神经元的偏置,每一层(输入层除外)的每个神经元只有一个偏置,每层的偏置个数取决于下一层神经元的个数;假设第 k 层有 m 个神经元, 表示第 k 层 m 个 b 组成的形状为 (m,) 的矩阵。
- 表示第 k 层网络的第 i 个神经元接收的加权和经过激活函数转换后的值;假设第 k 层有 m 个神经元, 表示第 k 层 m 个 a 组成的形状为 (m,) 的矩阵。
- 表示输出层的第 i 个神经元;假设输出层有 n 个神经元, 表示 n 个 y 组成的形状为 (n,) 的矩阵。
例如图 2 所示, 表示第 0 层网络的第 1 个神经元 到第 1 层网络的第 2 个神经元 之间的权重; 表示第 1 层网络的第 2 个神经元的偏置。
推理过程
神经网络的推理实际就是信息从输入层到输出层的传递与运算的过程,又叫前向传播。
在前向传播过程中,输入数据通过网络的各个连接进行传递,每个神经元接收到上一层神经元传递的信息,并根据自身的权重和激活函数进行计算,然后将计算结果传递给下一层神经元。通过多个层次的计算和传递,神经网络就具备了对输入数据进行复杂的处理的能力,并产生网络所需的端到端的预测或分类结果。
前向传播
如图 2 所示,套用前文「深度学习|引介:未来已来」介绍的 M-P 神经元结构��中的计算公式,我们用 统一表示激活函数,第 1 层第 1 个神经元的计算数学式为式 1:
更一般的,第 1 层神经元的计算用矩阵乘法表示为式 2:
如图 2 示例所示, 矩阵的具体元素分别为:
同理可得第 2 层神经元的计算用矩阵乘法表示为式 7:
输出层的计算用矩阵乘法表示为式 8:
权重参数
我们跳过神经网络的学习过程,假设我们已经学得该网络中所有的权重 W、偏置 B,这些参数都保存在 sample_weight.pkl 的文件中。
使用
Scikit-Learn现场训练一个 3 层神经网络模型:from sklearn.neural_network import MLPClassifier
import pickle
# 初始化并训练神经网络模型
# hidden_layer_sizes=(50, 100) 表示第 1 层 50 个神经元,第 2 层 100 个神经元
# max_iter=20 表示最大迭代次数为 20
# random_state=42 表示随机种子为 42
model = MLPClassifier(hidden_layer_sizes=(50, 100), max_iter=20, random_state=42)
# fit 表示训练模型,得到“最佳”的权重参数
model.fit(x_train, t_train)
# 保存模型的样本权重
weight_params = model.coefs_
bias_params = model.intercepts_
W = {'W'+str(i+1): weight_params[i] for i in range(len(weight_params))}
B = {'b'+str(i+1): bias_params[i] for i in range(len(bias_params))}
network = {**W, **B}
with open('sample_weight.pkl', 'wb') as f:
pickle.dump(network, f, -1)
我们将 sample_weight.pkl 加载到内存中,并查看这些参数:
import pickle
def init_network(model_file='sample_weight.pkl'):
with open(model_file, 'rb') as f:
network = pickle.load(f)
return network
# 查看模型权重参数
network = init_network()
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
print('W1 shape:', W1.shape)
print('W2 shape:', W2.shape)
print('W3 shape:', W3.shape)
print('b1 shape:', b1.shape)
print('b2 shape:', b2.shape)
print('b3 shape:', b3.shape)
# 可以看到加载的权重参数形状与上文前向传播中介绍的相符:
# W1 shape: (784, 50)
# W2 shape: (50, 100)
# W3 shape: (100, 10)
# b1 shape: (50,)
# b2 shape: (100,)
# b3 shape: (10,)
还可以直接查看模型的参数详情:
# 查看模型的权重参数
print('Layer 1 weights(W1):', W1)
print('Layer 2 weights(W2):', W2)
print('Layer 3 weights(W3):', W3)
print('Layer 1 biases(b1):', b1)
print('Layer 2 biases(b2):', b2)
print('Layer 3 biases(b3):', b3)
模型的参数详情大致如下:
Layer 1 weights(W1): [[-6.82908655e-134 2.73817863e-124 7.86086298e-131 ... -2.51158996e-136
-1.87750455e-135 6.86738504e-129]
...
[ 2.21426762e-123 -8.68062610e-138 9.65843942e-134 ... 4.04295961e-127
6.60988568e-132 -2.27081575e-123]]
Layer 2 weights(W2): [[-0.07216008 0.03237817 -0.30696488 ... -0.03664662 0.07658222
0.02644618]
...
[-0.09010675 -0.0677921 0.06192221 ... -0.16570688 -0.19768671
-0.08998851]]
Layer 3 weights(W3): [[ 5.22853581e-02 -1.26697444e-01 1.38297075e-01 5.23496136e-02
6.14831421e-02 -3.78902652e-02 1.76143522e-01 5.87658822e-02
1.36045963e-02 1.41049791e-01]
...
[-8.91916586e-03 -1.11147917e-01 1.88880477e-02 4.07215673e-02
6.97409219e-02 -1.20880403e-01 9.25973067e-02 -1.02178502e-03
-4.18847549e-02 3.56570368e-02]]
Layer 1 biases(b1): [ 0.0137522 0.03833063 -0.09956145 -0.03856783 -0.03449078 -0.04400879
...
-0.11450301 0.02820933 -0.11269283 -0.08658433 -0.04010245 -0.02471031
0.02431987 -0.02043312]
Layer 2 biases(b2): [ 0.04761845 0.0097227 -0.18579688 0.33545441 -0.00251954 -0.28249027
...
0.08788668 -0.29752006 -0.39022158 -0.14474585]
Layer 3 biases(b3): [ 0.05053622 -0.37941181 0.13039122 0.11149158 0.07131728 -0.24897518
-0.13914605 -0.51744395 0.53103882 -0.21369341]
现在只需将这些参数加载到神经网络模型 network(已在 Scikit-Learn 所训练的 MLPClassifier 模型中),即可通过该模型对 MNIST 中的手写数字进行推理。
推理与评估
直接使用 Scikit-Learn 所训练的 MLPClassifier 模型进行推理与测试:
# 用于评估模型的表现
from sklearn.metrics import classification_report, accuracy_score
# 进行推理(只取测试集进行推理效果测试,暂时丢弃训练集)
t_pred = model.predict(x_test)
# 输出结果
print(f"准确率: {accuracy_score(t_test, t_pred)}")
print(classification_report(t_test, t_pred))
# 准确率: 0.9499
# precision recall f1-score support
#
# 0 0.97 0.99 0.98 980
# 1 0.98 0.98 0.98 1135
# 2 0.95 0.95 0.95 1032
# 3 0.93 0.93 0.93 1010
# 4 0.97 0.92 0.94 982
# 5 0.95 0.93 0.94 892
# 6 0.97 0.96 0.96 958
# 7 0.97 0.94 0.96 1028
# 8 0.91 0.95 0.93 974
# 9 0.91 0.95 0.93 1009
#
# accuracy 0.95 10000
# macro avg 0.95 0.95 0.95 10000
#weighted avg 0.95 0.95 0.95 10000
我们可以将 model.predict() 推理调用中具体的计算过程通过 Python 代码实现出来。
使用该 network 对 MNIST 中的手写数字图像进行推理。
import numpy as np
def relu(x):
return np.maximum(0, x)
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
return exp_a / sum_exp_a
def predict(network, x):
"""推理方法
Args:
network: dict,包含了所有 W、B 等权重参数的“神经网络模型”;
x: nparray,输入数据,此处是图片的像素数组表示;
Returns:
y: nparray,推理结果,此处是图片分别为 0 ~ 9 的概率;
"""
W1, W2, W3 = network['W1'], network['W2'], network['W3'] # 第 1 层、第 2 层、输出层分别的权重
b1, b2, b3 = network['b1'], network['b2'], network['b3'] # 第 1 层、第 2 层、输出层分别的偏置
a1 = np.dot(x, W1) + b1 # 第 1 层加权和
z1 = relu(a1) # 第 1 层加权和经过 relu 激活函数转换的结果
a2 = np.dot(z1, W2) + b2 # 第 2 层加权和
z2 = relu(a2) # 第 2 层加权和经过 relu 激活函数转换的结果
a3 = np.dot(z2, W3) + b3 # 输出层加权和
y = softmax(a3) # 输出层加权和经过 softmax 激活函数转换的结果
return y
# 使用 network 模型进行推理测试
network = init_network()
print('Total number of samples:', len(x_test))
accuracy_cnt = 0
for i in range(len(x_test)):
y = predict(network, x_test.iloc[i])
# 获取概率最高的元素的索引
p = np.argmax(y)
# 判断是否与标签相符
if p == int(t_test.iloc[i]):
accuracy_cnt += 1
else:
print(f"Sample {i} - Predicted: {p}, Actual: {t_test.iloc[i]}")
print("Accuracy:", str(float(accuracy_cnt) / len(x_test)))
最终我们自己实现的推理代码输出结果如下:
Total number of samples: 10000
Sample 8 - Predicted: 6, Actual: 5
Sample 63 - Predicted: 2, Actual: 3
...
Sample 9980 - Predicted: 3, Actual: 2
Sample 9982 - Predicted: 8, Actual: 5
Accuracy: 0.9499
从输出可以看出,我们对测试集 x_test 中 10000 张图片进行推理,结果与 t_test 中标记的图片实际代表数字相符的概率是 94.99%,与 Scikit-Learn 的 MLPClassifier 封装的模型推理的结果一致,可见它其中所做的运算过程就是上述代码中表达的过程。
这个神经网络对 MNIST 数据集的手写数字识别的精度已经高达 94.99%,已经相当不错了。
结语
本文我们以手写数字识别任务为例,演示了神经网络的推理过程。通过使用 Scikit-Learn 的 MLPClassifier 进行推理,与手写的推理过程的推理结果进行对比,印证了我们的实现是对的。
神经网络的推理过程主要前向传播的过程,我们可以将输入数据通过网络的各个连接进行传递,每个神经元接收到上一层神经元传递的信息,并根据自身的�权重和激活函数进行计算,然后将计算结果传递给下一层神经元。通过多个层次的计算和传递,神经网络就具备了对输入数据进行复杂逻辑处理的能力,并产生网络所需的端到端的预测或分类结果。
PS:感谢每一位志同道合者的阅读,欢迎关注、点赞、评论!