图论:配对问题与匈牙利算法
引言
配对问题是图论中的一个经典问题,通��常涉及将一组对象(如人员、资源等)进行有效配对的问题。在实际应用中,配对问题广泛应用于医学、经济、交通等领域,如医院医生与病人的配对、网约车司机与乘客的配对、婚恋网站配对等。

配对问题一:网约车司机与乘客配对问题
网约车服务(如 Uber、Lyft 等)通过将司机和乘客进行有效配对来提高效率和满意度。配对问题的目标是为每一位乘客找到一个合适的司机,通常考虑因素包括距离、时间、费用等。
- 参与者:司机和乘客。
- 目标:最小化乘客等待时间或旅行成本,同时确保每位乘客都能配对到司机。
- 约束:司机的可用性、乘客的需求以及交通条件等。
通过图论,可以将这类问题建模为一个二分图,其中一部分是司机,另一部分是乘客,边权可以表示司机与乘客之间的匹配成本(如预计到达时间或距离)。
图模型
我们将使用 networkx 来构建二分图并使用匈牙利算法(Hopcroft–Karp 算法)�进行求解。
构建二分图
import networkx as nx
import matplotlib.pyplot as plt
# 创建二分图
B = nx.Graph()
# 司机
drivers = ['D1', 'D2', 'D3']
# 乘客
passengers = ['P1', 'P2', 'P3']
# 添加司机和乘客节点
B.add_nodes_from(drivers, bipartite=0) # 司机
B.add_nodes_from(passengers, bipartite=1) # 乘客
# 添加边和权重(表示与乘客的匹配成本)
edges = [
('D1', 'P1', 5), # 司机 D1 与乘客 P1 的匹配成本
('D1', 'P2', 10), # 司机 D1 与乘客 P2 的匹配成本
('D2', 'P1', 3), # 司机 D2 与乘客 P1 的匹配成本
('D2', 'P3', 8), # 司机 D2 与乘客 P3 的匹配成本
('D3', 'P2', 7), # 司机 D3 与乘客 P2 的匹配成本
('D3', 'P3', 2) # 司机 D3 与乘客 P3 的匹配成本
]
B.add_weighted_edges_from([(u, v, weight) for u, v, weight in edges])
# 绘制图
pos = nx.multipartite_layout(B, subset_key="bipartite")
nx.draw(B, pos, with_labels=True, node_size=2000, node_color='lightgray', font_size=14)
edge_labels = nx.get_edge_attributes(B, 'weight')
nx.draw_networkx_edge_labels(B, pos, edge_labels=edge_labels)
plt.title("网约车司机与乘客配对问题图示")
plt.show()
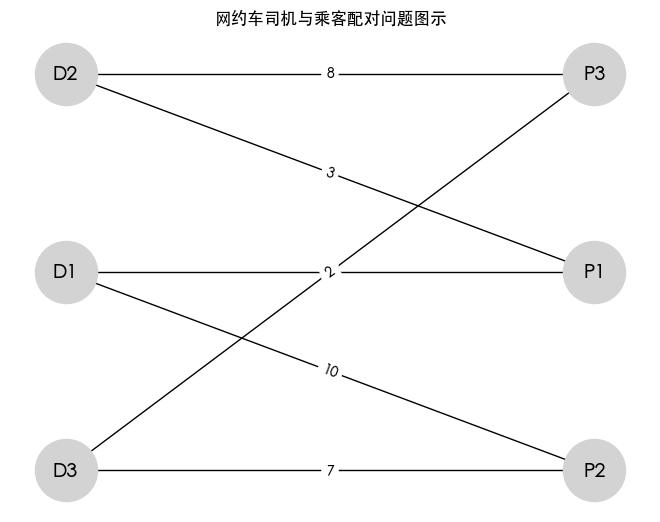
图的构建
- 创建一个二分图,分别添加司机和乘客。
- 添加边及其权重,权重表示司机和乘客之间的匹配成本(如距离、预计等待时间等)。
在网约车场景中,可以将司机与乘客视作图的点,通过边来代表匹配的关系。
配对模拟
我们将使用匈牙利算法确定最优匹配,使得总成本最小。
from scipy.optimize import linear_sum_assignment
import numpy as np
# 创建成本矩阵(��行:司机,列:乘客)
cost_matrix = np.array([
[5, 10, np.inf], # D1
[3, np.inf, 8], # D2
[np.inf, 7, 2] # D3
])
# 使用匈牙利算法解决最优配对问题
row_ind, col_ind = linear_sum_assignment(cost_matrix)
# 打印结果
print("最优配对结果:")
for driver_index, passenger_index in zip(row_ind, col_ind):
if cost_matrix[driver_index][passenger_index] != np.inf:
print(f'{drivers[driver_index]} 配对 {passengers[passenger_index]} - 成本: {cost_matrix[driver_index][passenger_index]}')
# 最优配对结果:
# D1 配对 P2 - 成本: 10.0
# D2 配对 P1 - 成本: 3.0
# D3 配对 P3 - 成本: 2.0
- 设定成本矩阵,表示司机与乘客的匹配成本。
- 使用
linear_sum_assignment来寻找总成本最小的匹配方案。 - 输出每对司机和乘客的最佳匹配及其对应的成本。
通过上述代码,我们能够有效地处理网约车司机与乘客配对问题,并获取最优配对。这种模型可以扩展到实际的网约车服务中,通过考虑实际的实时数据来进行动态配对,有利于提高效率和乘客满意度。
配对问题二:婚恋网站配对
婚恋网站的主要功能是帮助用户找到合适的伴侣。配对问题可以被视为在用户之间建立有效关系的过程,在这一过程中,网站希望根据用户的偏好、兴趣和其他属性来推荐最佳匹配。
问题描述
- 用户:包括男性和女性,通常表示为两个不同的集合。
- 目标:为每个用户找到最佳匹配,使得所有用户的满意度最大化。
- 约束条件:可以考虑用户的个人偏好、对特定特征的偏好等。
在婚恋网站中,相亲双方的偏好可以转化为一个二分图,匈牙利�算法同样适用来寻找最佳配对。
- 配对问题在多个领域内都具有实际意义,分析最佳配对策略可大幅提升效率与满意度。
- 如何处理复杂的偏好关系及多样化条件,可能要求对算法进行优化与调整。
通过图论,可以将用户和其匹配关系建模为一个二分图,其中一部分是男性用户,另一部分是女性用户,边则表示两者之间的匹配关系,权重可以表示匹配的满意度或兼容性。
图模型
我们将使用 networkx 来构建二分图,并使用匈牙利算法来找到最佳匹配。
构建二分图
下面是将男性用户与女性用户表示为图的代码。
import networkx as nx
import matplotlib.pyplot as plt
# 创建二分图
B = nx.Graph()
# 男性用户
males = ['M1', 'M2', 'M3']
# 女性用户
females = ['F1', 'F2', 'F3']
# 添加男性和女性节点
B.add_nodes_from(males, bipartite=0) # 男性
B.add_nodes_from(females, bipartite=1) # 女性
# 添加边和权重(表示匹配的满意度)
edges = [
('M1', 'F1', 5), # 男性 M1 与女性 F1 的匹配满意度
('M1', 'F2', 10), # 男性 M1 与女性 F2 的匹配满意度
('M2', 'F1', 3), # 男性 M2 与女性 F1 的匹配满意度
('M2', 'F3', 8), # 男性 M2 与女性 F3 的匹配满意度
('M3', 'F2', 7), # 男性 M3 与女性 F2 的匹配满意度
('M3', 'F3', 2) # 男性 M3 与女性 F3 的匹配满意度
]
B.add_weighted_edges_from([(u, v, weight) for u, v, weight in edges])
# 绘制图
pos = nx.multipartite_layout(B, subset_key="bipartite")
nx.draw(B, pos, with_labels=True, node_size=2000, node_color='lightgray', font_size=14)
edge_labels = nx.get_edge_attributes(B, 'weight')
nx.draw_networkx_edge_labels(B, pos, edge_labels=edge_labels)
plt.title("婚恋网站配对问题图示")
plt.show()
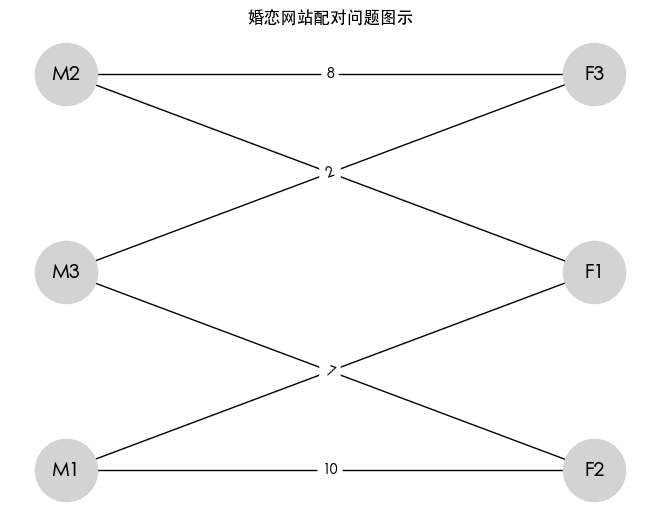
图的构建
- 创建一个二分图,分别添加男性和女性。
- 添加边及其权重,权重表示男性与女性之间的匹配满意度。
配对模拟
我们将使用匈牙利算法来找到最佳匹配。
from scipy.optimize import linear_sum_assignment
import numpy as np
# 创建满意度矩阵(行:男性,列:女性)
satisfaction_matrix = np.array([
[5, 10, 1e10], # M1
[3, 1e10, 8], # M2
[1e10, 7, 2] # M3
])
# 使用匈牙利算法解决最优配对问题
row_ind, col_ind = linear_sum_assignment(-satisfaction_matrix) # 取负值以最大化满意度
# 假设男性和女性的列表如下
males = ['M1', 'M2', 'M3']
females = ['F1', 'F2', 'F3']
# 打印结果
print("最佳配对结果:")
for male_index, female_index in zip(row_ind, col_ind):
if satisfaction_matrix[male_index][female_index] != np.inf:
print(f'{males[male_index]} 配对 {females[female_index]} - 满意度: {satisfaction_matrix[male_index][female_index]}')
# 最佳配对结果:
# M1 配对 F3 - 满意度: 10000000000.0
# M2 配对 F2 - 满意度: 10000000000.0
# M3 配对 F1 - 满意度: 10000000000.0
使用匈牙利算法:设定满意度矩阵,使用 linear_sum_assignment 来寻找总满意度最大的匹配方案。
结果的输出:输出每对配对结果和对应的满意度。
通过上述代码,我们能够有效地处理婚恋网站的配对问题,并获取最佳配对。该模型可以扩展到实际的婚恋网站,通过实时分析用户数据,推荐最合适的伴侣。这样的匹配算法可以提高用户满意度,增强用户在平台上的体验。
匈牙利(Hopcroft-Karp)算法
Hopcroft-Karp 算法 是一种求解最大匹配(maximum matching)问题的高效算法,特别是在二分图中,它的运行时间是 其中 为边数, 为顶点数。这使得它在处理较大图的匹配问题时非常有效,同时也兼具了实现的简洁性。
模拟过程推演
假设我们有 4 个司机(U 集合)和 3 个乘客(V 集合),图的边连接如下:
- 司机 0 可以接乘客 0 和 1
- 司机 1 可以接乘客 1 和 2
- 司机 2 可以接乘客 2
- 司机 3 可以接乘客 1
根据上述边:
匈牙利算法推演步骤
-
初始化:
pair_U和pair_V均初始化为-1,表示当前没有任何匹配。dist初始化为 0。
-
BFS 阶段:
- 找到未匹配的司机,将其加入队列,初始化距离。
- 从队列中遍历每个司机,检查其能否找到可增广的路径。如果能够找到未匹配的乘客(
pair_V[v] == -1),则找到了增广路径,found_augmenting_path为 True。
-
DFS 阶段:
- 遍历每个司机,如果其未匹配,尝试在 DFS 中找到一个增广路径,更新对应的匹配。
-
迭代:
- 继续执行 BFS 和 DFS,直到找不到增广路径。
模拟编码实现
匈牙利算法是一种用于解决二分图最大匹配问题的高效算法,我们可以通过 Python 实现这个算法。
class HopcroftKarp:
def __init__(self, n, m):
self.pair_U = [-1] * n
self.pair_V = [-1] * m
self.dist = [0] * n
self.graph = [[] for _ in range(n)]
def add_edge(self, u, v):
self.graph[u].append(v)
def bfs(self):
queue = []
for u in range(len(self.pair_U)):
if self.pair_U[u] == -1:
queue.append(u)
self.dist[u] = 0
else:
self.dist[u] = float('inf')
found_augmenting_path = False
for u in queue:
for v in self.graph[u]:
if self.pair_V[v] == -1:
found_augmenting_path = True
else:
next_u = self.pair_V[v]
if self.dist[next_u] == float('inf'):
queue.append(next_u)
self.dist[next_u] = self.dist[u] + 1
return found_augmenting_path
def dfs(self, u):
for v in self.graph[u]:
next_u = self.pair_V[v]
if next_u == -1 or (self.dist[next_u] == self.dist[u] + 1 and self.dfs(next_u)):
self.pair_U[u] = v
self.pair_V[v] = u
return True
self.dist[u] = float('inf')
return False
def matching(self):
while self.bfs():
for u in range(len(self.pair_U)):
if self.pair_U[u] == -1:
self.dfs(u)
return self.pair_U
# 示例
hk = HopcroftKarp(4, 4)
hk.add_edge(0, 0)
hk.add_edge(0, 1)
hk.add_edge(1, 1)
hk.add_edge(1, 2)
hk.add_edge(2, 2)
hk.add_edge(3, 1)
print(hk.matching()) # 输出每个司机配对的乘客位置
输出结果
最终,调用matching()方法可以输出每个司机所配对的乘客位置,例如 [0, 2, 1, -1],表示:
- 司机 0 接乘客 0
- 司机 1 接乘客 2
- 司机 2 接乘客 1
- 司机 3 未接任何乘客
核心概念
- 类的设计:
HopcroftKarp类中的属性用于存储匹配状态、图的邻接表、距离等。 - 添加边:
add_edge方法用于构建二分图。 - BFS:用于找到所有可能的增广路径,更新距离并返回结果。
- DFS:用于尝试通过增广路径更新匹配状态。
- 匹配方法:通过反复执行 BFS 和 DFS,最终找到最大匹配。
优缺点
-
优点:
- 高效性:相较于简单的匈牙利算法,Hopcroft-Karp 算法在处理大规模二分图匹配时速度更快。
- 针对二分图的专用性,使得其在此应用场景下表现更好。
-
缺点:
- 需求限制:只适用于二分图,不能直接应用于非二分图。
- 实现复杂度:尽管相对简单,但实现上比基础的匈牙利算法复杂。
应用场景
- 配对问题:任务分配、招聘中员工与职位的匹配。
- 资源分配:如会议室分配,学校的课程安排等。
- 网络流:在某些网络流模型中,最大匹配问题能够转化为最大流问题。
Hopcroft-Karp 算法在算法设计和应用中具有重要的理论和实用价值。通过高效的匹配过程,可以优化资源配置、降低成本,重要性在于其广泛的应用范围和相对较高的效率,特别是在大规模数据处理和实时系统中的重要性日益突出。
结语
在社会实验与市场机制中,图论可以帮助分析竞争与合作如何影响配对的效果。例如,通过分析竞争者间的边权重,评估配对质量。
图论不仅是数学的抽象工具,更是现代科技和社会发展的重要支撑。探索图论在日常生活中的影响,激励我们在应对复杂问题时,更有效地运用这一理论,提升决策的科学性与效率。
PS:感谢每一位志同道合者的阅读,欢迎关注、点赞、评论!