误差逆传播:梯度速解
引言
我们知道训练神经网络模型的核心是以损失函数为基准来调整优化网络参数,使得网络的输出尽可能接近真实标签。在神经网络中,优化网络参数需要计算每个权重参数的梯度,不同的网络结构,计算梯度的方式和复杂度往往大不相同,有没有一种算法,即可以有效囊括所有类型的网络结构的梯度计算,又足以保证梯度计算的高效性?答案就是我们今天要讲的误差逆传播算法。
链式法则
要理解误差逆传播算法,需要先了解微分中链式法则的概念。链式法则是微分中的基本法则,可用于求解复合函数的导数。
如果某个函数由复合函数表示,则该复合函数的导数可以用构成该复合函数的各个函数的导数的乘积表示。
以式 1 所示的复合函数为例:
通过链式法则求解 :
可见一个复杂函数的求导问题可以分解为组成该复杂函数的局部函数的求导问题,我们完全可以将复杂函数的导数等价的表示为其所有局部函数的导数的乘积。
在神经网络中,误差逆传播算法就是利用链式法则来计算网络中每个参数的梯度。
误差逆传播
在前文「深度学习|模型训练:手写 SimpleNet」中,我们演示了使用数值微分方式求梯度的过程,数值微分的方式求梯度简单、易于理解与实现,但它的问题是计算效率很低。在 SimpleNet 的示例中,我们使用数值微分法训练所需时间长达 27.7 小时,几乎是不可用的状态。
那么有没有更高效的替代方式呢?终于轮到神经网络的主角算法误差逆传播出场了!
参考上文求复合函数(式 1)关于 x 的导数 的求解过程,给定 x 与 y,按照函数式求解 z 的正向计算的过程,就好比神经网络的前向传播(Forward Propagation),而沿着函数正向计算的链路,从最末端逆向计算每个局部函数的导数,最终相乘从而得到该复杂函数的导数,就好比神经网络的逆传播(Backward Propagation)。
前向传播(Forward Propagation):将输入数据通过网络进行运算,得到网络的输出、输出与目标值之间的误差。 逆传播(Backward Propagation):从输出层开始,将误差逆传播到隐藏层,直到输入层。逆传播过程可以计算每个权重的梯度,即误差相对于每个权重的偏导数。
误差逆传播(error BackPropagation,简称 BP)就是基于数学推导的解析性(相对于数值微分的数值性)梯度计算方法(符号微分,Symbolic Differentiation),按照数学中求导的链式法则,局部导数会按正向传播的反方向传递。
以求解 为例,我们可以用如下图 1 中红色箭头所指过程表示该求导过程:
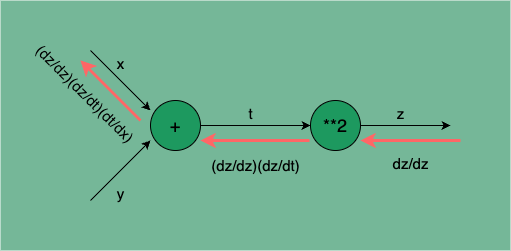
图 1:局部导数沿着函数正向计算的链路逆向传播
图 1 所示从左到右是复合函数的正向传播过程,表示的是 , 的正向计算过程。
从右往左是复合函数的逆传播过程,通过逆传播求函数关于 x 的导数 ,只需要沿着正向计算的链路逆向计算每个局部函数的导数,例如从输出 z 到 z 本身的导数是 ,从 z 到 t 的导数是 ,从 t 到 x 的导数是 ,最终将每个环节的导数相乘即是该复合函数的导数 (其中 可忽略)。这就是 BP 算法的基本思想。
不难发现,神经网络中的前向传播都是由一些简单的加法、乘法等常用的运算复合而成,而神经网络的逆传播就是求解网络整个“复合函数”关于网络各层中权重参数的梯度。
我们在了解了 BP 算法的基本思路后,不难得出这些梯度的求解方式:沿着网络的正向运算过程,反向从输出层开始,往前计算每层运算的局部梯度,然后将求解目标参数梯度的完整链路上的所有局部��梯度相乘,得到的就是目标参数的梯度。
接下来我们可以找到在逆传播过程中,使用 BP 算法求解加法、乘法等常用运算的梯度的规律。应用这些规律,我们可以在神经网络的逆传播运算过程中高效地计算梯度。
加法的逆传播
以 为例,其梯度 (,) 永远为 (1, 1)。
因此加法运算在逆传播时,总是将下游梯度乘以 1,即原封不动传递给上游。
我们可以使用 AddLayer 类实现加法运算的前向传播与逆传播:
class AddLayer:
"""
加法运算的前向传播与逆传播
"""
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
"""
前向传播
Args:
x: 输入 x
y: 输入 y
Returns:
out: 输出
"""
out = x + y
return out
def backward(self, dout):
"""
逆传播
Args:
dout: 上游梯度
Returns:
dx: x 的梯度
dy: y 的梯度
"""
dx = dout * 1
dy = dout * 1
return dx, dy
这里采用了
标准层封装的方式来实现加法运算,将加法运算封装成了一个可以被任意结构的神经网络直接复用的小组件,其他如乘法运算、激活函数、损失函数等我们都将采用这样的实现方式。采用这样的封装方式,我们就可以在组装我们想要的网络时随意选择我们想要的组件(基本运算单元)。在实际的生产级机器学习框架(如 Scikit-learn、TensorFlow、PyTorch 等)中,这些底层运算封装也正是采用了这样的方式实现。
乘法的逆传播
以 为例,其梯度 (,) = (y, x)。
因此乘法运算的逆传播时,总是将下游梯度乘以上游相乘参数的值(翻转值)。比如 x 与 y 相乘,求关于 x 的偏导数时,y 是 x 的翻转值;求关于 y 的偏导数时,x 是 y 的翻转值。
同上,我们用 MulLayer 类实现乘法运算的前向传播与逆传播:
class MulLayer:
"""
乘法运算的前向传播与逆传播
"""
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
"""
前向传播
Args:
x: 输入 x
y: 输入 y
Returns:
out: 输出
"""
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
"""
逆传播
Args:
dout: 上游梯度
Returns:
dx: x 的梯度
dy: y 的梯度
"""
dx = dout * self.y
dy = dout * self.x
return dx, dy
逆传播求梯度
以 为例,求 = (100, 2, 300) 处的梯度。
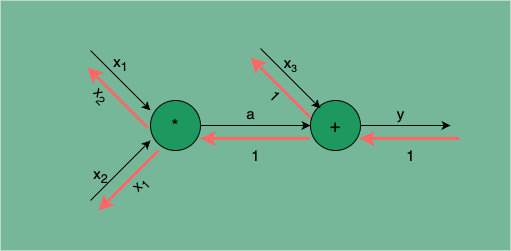
图 2:逆传播求梯度的计算链路,红色箭头表示逆传播的计算方向
式 的计算链路如图 2,我们可以直接通过上文的 MulLayer 和 AddLayer 进行前向传播求 y,以及逆传播求关于 的梯度。
x1, x2, x3 = 100, 2, 300
mul_layer = MulLayer()
add_layer = AddLayer()
# forward
a = mul_layer.forward(x1, x2)
y = add_layer.forward(a, x3)
print(y) # 500
# backward
da, dx3 = add_layer.backward(1)
dx1, dx2 = mul_layer.backward(da)
print(dx1, dx2, dx3) # (x2, x1, 1) = (2, 100, 1)
运行结果与图 2 中所示 (输入 各自的反向红色箭头是它们各自的梯度)一致,可见逆传播求梯度的结果是符合预期的。
以上逆传播求梯度过程可以直接应用在神经网络中对数组和矩阵的运算上:
x1, x2, x3 = np.array([100, 101, 102]), np.array([2, 3, 4]), np.array([300, 301, 302])
mul_layer = MulLayer()
add_layer = AddLayer()
# forward
a = mul_layer.forward(x1, x2)
y = add_layer.forward(a, x3)
print(y) # [500 604 710]
# backward
da, dx3 = add_layer.backward(1)
dx1, dx2 = mul_layer.backward(da)
print(dx1, dx2, dx3) # (x2, x1, 1) = [2 3 4] [100 101 102] 1
SoftmaxWithLoss 层
我们知道神经网络模型的训练过程就是根据损失函数关于权重参数的梯度优化权重参数的过程,其中求解损失函数关于权重参数的梯度是运算的核心。而损失函数往往是神经网络正向传播中的最后一个环节(训练过程的最后一个过程是损失函数,推理过程则一般不需要计算损失),根据 BP 算法的思路,在逆传播过程中,求解损失函数的“局部梯度”就成了求解权重参数梯度的第一步。
由于在多分类任务中,神经网络模型经常使用 Softmax 函数来对最终输出做归一化处理,我们在封装损失函数时,通常会将 Softmax 函数与损失函数结合在一起,这样的结构我们称之为SoftmaxWithLoss层。
下面我们以交叉熵误差为例,通过实现一个 SoftmaxWithLoss 层来�演示 BP 算法及其“局部梯度”的求解过程。
假定网络的输出层有 n 个神经元(n 个分类类别),则 SoftmaxWithLoss 层的计算过程如图 3 所示:
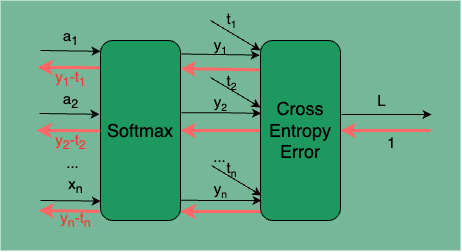
图 3:SoftmaxWithLoss 的计算过程
从前面的层输入的是 ,Softmax 层输出的是 ,实际结果分别是 ,Cross Entropy Error 输出的损失是 L。
正向传播
Softmax 往往作为网络输出层的激活函数,对网络的输出做最后的归一化处理;而在模型训练时,Softmax 的输出与实际结果作为损失函数的输入,可以计算出模型训练所需的损失值。可见 SoftmaxWithLoss 层实际就是经过了 Softmax 计算和 Loss Function 计算两个过程。
其中 Softmax 计算过程如式 2:
Loss Function(交叉熵误差)计算过程如式 3:
合并式 2 和式 3,SoftmaxWithLoss 层的正向传播总计算式 4:
SoftmaxWithLoss 层的正向传播分布计算过程:
- 指数运算:计算每个输入 的自然指数 ;
- 加法运算:计算所有输入的自然指数之和 ;
- 除法运算:计算所有输入的自然指数之和的倒数 ;
- 乘法运算:计算每个输入 的自然指数与所有输入的自然指数之和的倒数的乘积 ;
- 对数运算:计算每个输入 的自然指数与所有输入的自然指数之和的倒数的乘积的对数 ;
- 乘法运算:计算每个输入 的自然指数与所有输入的自然指数之和的倒数的乘积的对数与实际结果 的乘积 ;
- 加法运算:计算所有输入的自然指数与所有输入的自然指数之和的倒数的乘积的对数与实际结果的乘积之和 。
- 乘法运算:计算所有输入的自然指数与所有输入的自然指数之和的倒数的乘积的对数与实际结果的乘积之和的相反数 。
正向传播计算的是 SoftmaxWithLoss 根据输入 a 和真实结果 t 计算误差的过程;相对的,我们再看如何使用逆传播迅速计算 SoftmaxWithLoss 层的损失梯度(损失函数关于输入 a 的梯度)。
逆传播
逆传播计算过程是沿着正向传播过程的反方向进行的,首先误差梯度的初始值永远是 = 1,逆传播的计算过程如下:
- 乘法求导(8):
该步是 与 做乘法运算,逆传播计算 的局部梯度取乘数 -1,此时梯度为 ;
- 加法求导(7):
该步是对各项 做加法运算,逆传播计算各项 的局部梯度取原值 -1,此时各项梯度为 -1;
- 乘法求导(6):
该步是 与 做乘法运算,逆传播计算 的局部梯度取乘数 ,此时梯度为 ;
- 对数求导(5):
该步是对 做对数运算,逆传播计算 的局部梯度取自变量的倒数 ,此时梯度为 ;
- 乘法求导(4):
该步是 与 做乘法运算,逆传播计算 的局部梯度取乘数 ,此时梯度为:
因为 分别与 n 项 做乘法运算,逆传播计算局部梯度求所有分支的和 - ,此时梯度为:
逆传播计算 的局部梯度取乘数 ,此时梯度为:
- 除法求导(3):
该步是用 除 1,逆传播计算 的局部梯度为:,此时梯度为:
此处因为 是 one-hot 编码,有且仅有一个 k 令 为 1,其他 t 全是 0,即 ,因此此时梯度为:
- 加法求导(2):
该步是对各项 做加法运算,逆传播计算各项 的局部梯度取原值为:
- 指数求导(1):
该步是自然指数运算,逆传播求 的局部梯度取自身为:;
因为 被分别使用于正向传播 2 和正向转播 4 的运算,逆传播求 的梯度前,需要将正向传播 2 和正向转播 4处的梯度(即 temp-2 与 temp-1)求和作为 的逆传播输入值,即:
因此此处的梯度为:
即通过 SoftmaxWithLoss 层的逆传播过程推演计算,我们得到了损失函数 L 关于输入 的梯度为式 5:
相比数值微分法求梯度需要大量计算,我们可以直接利用公式 5 求损失函数 L 关于输入 的梯度,这将极大提高计算效率。
代码实现参考
根据上文 SoftmaxWithLoss 层的正向传播算式 4 与逆传播算式 5,我们可以轻易实现 SoftmaxWithLoss 层:
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
"""
前向传播
Args:
x: 输入数据
t: 监督数据
Returns:
float: 损失
"""
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
"""
逆传播
Args:
dout: 上游梯度
Returns:
np.ndarray: 损失关于输入 x 的梯度
"""
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
测试 SoftmaxWithLoss 层的正向传播与逆传播:
softmax_with_loss = SoftmaxWithLoss()
# 示例数据
a = np.array([[1.0, 2.0, 0.5], [0.0, 1.0, 1.0]]) # 未归一化输出
t = np.array([[1, 0, 0], [0, 1, 0]]) # one-hot 编码标签
# 前向传播
loss = softmax_with_loss.forward(a, t)
# 逆传播
da = softmax_with_loss.backward()
print("Softmax Result:\n", softmax_with_loss.y)
print("Cross Entropy Loss:", loss)
print("Gradient:\n", da)
# Softmax Result:
# [[0.2312239 0.62853172 0.14024438]
# [0.1553624 0.4223188 0.4223188 ]]
# Cross Entropy Loss: 1.1631814594485623
# Gradient:
# [[-0.38438805 0.31426586 0.07012219]
# [ 0.0776812 -0.2888406 0.2111594 ]]
将以上逆传播求梯度的过程套用在神经网络损失函数关于权重参数的梯度求解上,我们就实现一个高效的神经网络学习算法,这就是 BP 算法。
交叉熵误差概��念回顾
以多分类任务为例,我们知道其交叉熵误差的计算公式为:
其中:
- 是模型的输出,通常是经过 softmax 函数处理得到的预测概率分布。
- 是真实标签,通常是 one-hot 编码表示的实际结果。
使用 Python 代码实现的交叉熵误差函数:
import numpy as np
def cross_entropy_error(y, t):
"""
交叉熵误差函数
Args:
y: 神经网络的输出
t: 监督数据
Returns:
float: 交叉熵误差
"""
# 监督数据是 one-hot-vector 的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
Softmax 函数实现回顾
def softmax(x):
"""归一化指数函数"""
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
结语
我们通过 BP 算法的正向传播与逆传播过程,演示了如何高效计算神经网络的梯度。通过 BP 算法,我们可以直接计算损失函数关于权重参数的梯度,而不需要通过数值微分法进行梯度计算,这将大大提高神经网络的训练效率。
BP 算法是迄今最成功的神经网络学习算法,通常神经网络(不限于前馈神经网络)都使用 BP 算法进行训练。“BP 网络”特指使用 BP 算法训练的多层前馈神经网络。
BP 算法实质是 LMS(Least Mean Square)算法的推广。LMS 试图使网络的输出均方误差最小化,用于神经元激活函数可微的感知机学习,LMS 推广到由非线性可微神经元组成的多层前馈网络,就是 BP 算法。
PS:感谢每一位志同道合者的阅读,欢迎关注、点赞、评论!